
디지안의 개발일지
[TIL] High performance with idiomatic Kotlin 본문
이 글은 High performance with idiomatic Kotlin을 보고 배운 내용에 대해서 서술합니다.
우리가 좋은 성능을 발휘하는 애플리케이션을 만드려는 이유는 간단하다. 느리면 사용자가 내가 개발한 소프트웨어를 사용하지 않기 때문이다. 이 글에서 소개하는 내용은 다음과 같다.
- 소프트웨어 제품을 구축할 때 고성능이 필수적인 이유
- 성능 문제의 가장 일반적인 이유
- Kotlin에서의 성능 향상 효과
소프트웨어 제품을 구축할 때 고성능이 필수적인 이유
연구 에 따르면 사용자는 빠른 로딩 페이지를 높이 평가한다. 여기서 주목해야할 점은 결과를 빠르게 보여주는 것이 아니라 진행 상황을 제공한다는 것이다. 진행 상황만 제공이 되도 소프트웨어로 얻으려는 목표를 빠르게 달성하고 있다고 만족감을 느낀다고 한다.
그리고 사람들이 낮은 성능에 대해서는 다음과 같이 반응한다고 한다.
- 40%의 사람이 화면을 로드하는데 3초 이상 걸리는 웹사이트를 포기한다.
- 웹사이트 선능에 불만족한 사용자의 79%가 같은 사이트에서 다시 구매할 가능성이 적다.
- 낮은 성능이 고객의 만족도 뿐만 아니라 제품의 브랜드를 손상시킨다.
- 사용자의 44%가 온라인에서 나쁜 경험에 대해 지인들에게 말하기 때문
성능 문제의 가장 일반적인 이유
Kotlin은 JVM 언어이므로 상위 수준의 JVM 아키텍처를 검토하여 성능 병목 현상의 영향을 받는 영역을 식별해야한다.
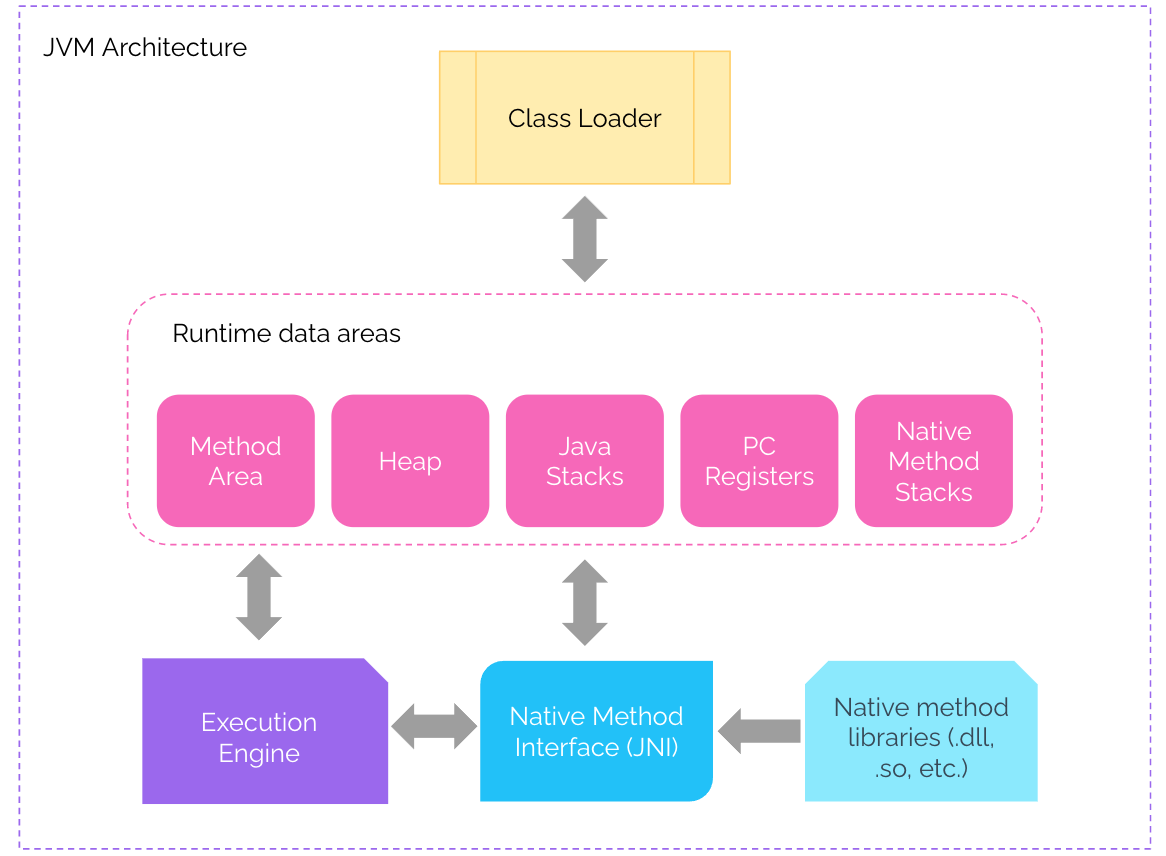
- 메모리 관리(Garbage Collection)
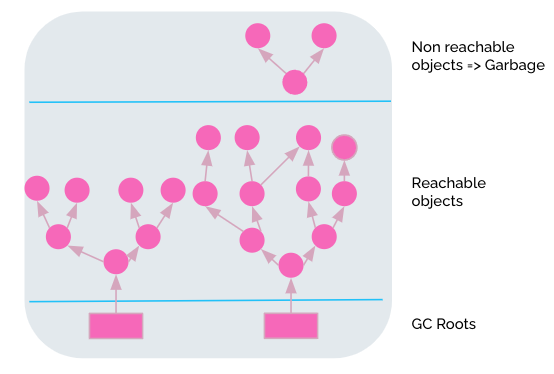
GC는 메모리의 재사용을 위해 더 이상 참조되지 않는 개체를 찾아 제거하는 역할을 한다. 이 방법은 적어도 이론상으로 메모리 누수 및 기타 메모리 관련 문제를 제거한다. 자바에서 객체는 각 객체마다 참조를 하고 있다. 이 참조하고 있는 것의 시작을 GC root라고 부른다. GC root가 될 수 있는 것은 로컬 변수, 정적 변수, 활성 스레드, JNI 등이 될 수 있다. GC는 참조 트리의 무결성을 달성하기 어려워질 때 그 순간 world stop 또는 GC pause가 일어나서 모든 쓰레드의 실행이 중단되고 아래에서 설명하는 compacting 단계와 연결된다.
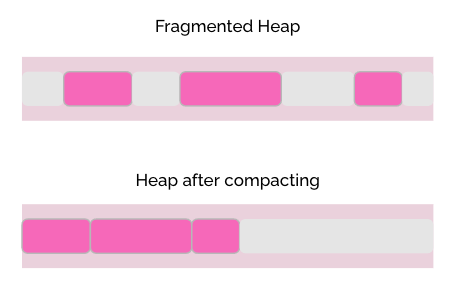
- 힙 단편화
힙 조각화에 대해 이야기할 때 발생할 수 있는 문제는 다음에 사용할 여유 메모리 블록을 찾는 것이 어려워졌을 때를 의미한다. 예를 들어, 할당된 메모리 블록 사이의 공간이 너무 커서 JVM이 새 객체에 대한 메모리를 할당할 수 없을 수도 있다. 이 문제를 해결하기 위해서는 메모리를 압축하는 과정이 필요하다.
- 리소스 및 메모리 누수
리로스 누수는 사용 완료한 리소스에 대해서 해제되지 않을 때 발생한다. 일반적으로 파일 작업이 주로 이룬다. 더 이상 사용되지 않는 객체에 대한 참조가 여전히 다른 객체에 저장되어 있으면 메모리 누수가 발생한다.
코틀린 성능 향상 효과
- 여러 CPU에서 병렬 처리를 위한 순수 함수
순수 함수는 동일한 매개변수에 대해 동일한 값을 반환한다. 코틀린의 경우 컴파일러가 병렬처리를 하는 경우에는 함수 호출을 최적화하여 결과로 저장하고 있을 수 있다. 그래서 특수한 상황에서 순수 함수가 성능적으로 유리하다.
- 코드를 재사용하는 고차 함수
고차함수를 사용하면 함수를 매개변수로 전달하거나 함수를 반환하거나 이 두가지를 동시에 수행할 수 있다. 이를 통해 기존 동작을 재활용할 수 있다.
fun titleStartsWithS(book: Book) = book.title.startsWith("S")
fun lengthOfTitleGraterThan5(book: Book) = book.title.length > 5
fun authorStartsWithB(book: Book) = book.author.startsWith("B")
val book1 = Book("Start with why", "Simon Sinek")
val book2 = Book("Dare to lead", "Brene Brown")
val books = listOf(book1, book2)
// this code should be improved
val filteredBooks = books
.filter(::titleStartsWithS)
.filter(::authorStartsWithB)
.filter(::lengthOfTitleGraterThan5)filter하는 로직을 위와 같이 구성하면 필터 기능이 내부 루프이기 때문에 성능 문제를 발생할 수 있다. 그래서 다음과 같이 3가지 방법으로 해결 할 수도 있다.
// 1st solution = dedicated predicat
fun allFilters(book: Book): Boolean = titleStartsWithS(book)
&& lengthOfTitleGraterThan5(book)
&& authorStartsWithB(book)
// 2nd solution = anonymous function
books.filter(fun(book: Book) = titleStartsWithS(book)
&& lengthOfTitleGraterThan5(book)
&& authorStartsWithB(book))
// 3rd solution = function composition
inline infix fun <P> ((P) -> Boolean).and(crossinline predicate: (P) -> Boolean): (P) -> Boolean {
return { p: P -> this(p) && predicate(p) }
}
books.filter(
::titleStartsWithS
and ::authorStartsWithB
and ::lengthOfTitleGraterThan5
)- 1st : 조건에 따라 루프를 돌면서 확인하는 것이 아니라 한번의 루프에서 각 조건을 확인한다.
- 2nd : 익명 함수를 구현한다.
- 3rd : 함수를 조합하는 함수를 만든다.
주의해야할 점은 ::titleStartsWithS, ::authorStartsWithB, ::lengthOfTitleGreaterThan5 등의 호출은 일반 함수처럼 쉽게 재사용할 수 있는 새 함수 인스턴스를 반환한다.
- 함수를 값으로 취급하는 람다
람다는 코드 블록을 함수 매개변수로 직접 전달한 것이다. 이는 함수를 값으로 취급한다는 것을 의미한다. 그리고 클로저 는 블록 밖의 정의된 변수에 접근할 수 있는 함수를 의미한다. 클로저는 해당 함수 외부에서 변수를 캡처하기 때문에 캡처링 람다라고도 부른다. Java는 final 한 값만 캡처링할 수 있지만 Kotlin은 var, val 관련 없이 캡처링을 할 수 있다.
kotlin의 val는 복사될 때, Java와 같이 값이 복사되고 var는 Ref 클래스의 인스턴스로 저장된다. 여기서 주목해야하는 점은 클로저를 만드는 것은 새 Function 인스턴스를 생성한다는 것이다. 그래서 너무 자주사용하면 오버헤드를 일으킬 수 있다.
- 인라인 함수와 구체화된 유형
인라인 함수는 람다의 오버헤드를 제거하는 역할을 한다.
- 컬렉션 및 시퀀스
컬렉션으로 작업할 때 일반적인 권장 선호 사항은 읽기 전용 컬렉션을 사용하는 것이다. 이를 통해 상태 불일치와 관련된 버그를 방지할 수 있기 때문이다. 그 다음에는 컬렉션을 사용할지 시퀀스를 사용할지 선택해야한다. 매우 많은 수의 요소를 처리해야 하는 경우에는 시퀀스를 선택해야한다.
다음 예제를 보자. 시퀀스로 작업이 수행되면 지연 평가에 대해서는 중간 값을 저장하지 않는다. 아래 예제에서는 요소마다 컬렉션 함수들이 처리가 되기 때문에 first() 를 만나면 다음 연산을 하지 않는다. 그렇기 때문에 속도가 압도적으로 시퀀스가 빠르다.
fun main() {
smallList()
smallSequence()
}
fun smallList() = (0..5)
.filter { print("list filter($it) "); it % 2 == 0 }
.map { print("list map($it) "); it * it }
.first()
fun smallSequence() = (0..5)
.asSequence()
.filter { print("seq filter($it) "); it % 2 == 0 }
.map { print("seq map($it) "); it * it }
.first()
// output
list filter(0) list filter(1) list filter(2) list filter(3) list filter(4) list filter(5) list map(0) list map(2) list map(4) 11 ms
seq filter(0) seq map(0) 6 ms- 불변성
불변성은 데이터 클래스를 사용하여 Kotlin에서 기본적으로 사용할 수 있으며 toString(), hashCode(), hashCode(), equal(), copy(), componentN() 을 구현하지 않고 그대로 사용할 수 있다.
interface ValueHolder<V> {
val value: V
}
class IntHolder : ValueHolder<Int> {
override val value: Int
get() = Random().nextInt()
}
fun main() {
val sample = IntHolder()
println(sample.value) //260078462
println(sample.value) //1657381068
}
// immutability by default
data class ImmutableKey(val name: String? = null)- 일회용 패턴
Disposable 패턴은 리소스 관리에 사용되는 패턴으로 리소스 누수를 방지하기 위해 사용하면 매우 유용하다. Kotlin에서 이 작업은 close 또는 dispose 메소드를 호출하여 리소스를 해제하는 확장 기능으로 사용한다.
inputStream.use {
outputStream.use {
// do something with the streams
outputStream.write(inputStream.read())
}
}
// improved option
arrayOf(inputStream, outputStream).use {
// do something with the streams
outputStream.write(inputStream.read())
}
// use implementation
private inline fun <T : Closeable?> Array<T>.use(block: ()->Unit) {
// implementation
}- 문자열 템플릿
Kotlin의 문자열 템플릿은 내부적으로 StringBuilder 클래스를 사용하기 때문에 String을 + 하는 것보다 성능상의 이점을 얻을 수 있습니다. Kotlin 1.5.20 부터는 StringConcatFactory.makeConcatWithConstants() 을 사용한다.
- @JvmField
@JvmField는 Kotlin의 속성을 필드로 사용할 수 있게 한다. 그래서 getter 및 setter를 호출하지 못하게 할 수 있다.
- Ranges
ranges를 사용할 때는 선택한 접근 방식에 따라 런타임에 오버헤드가 발생하거나 발생하지 않을 수 있다.
- null이 포함된 경우 아래와 같이 쓸데 없는 객체가 생성된다.
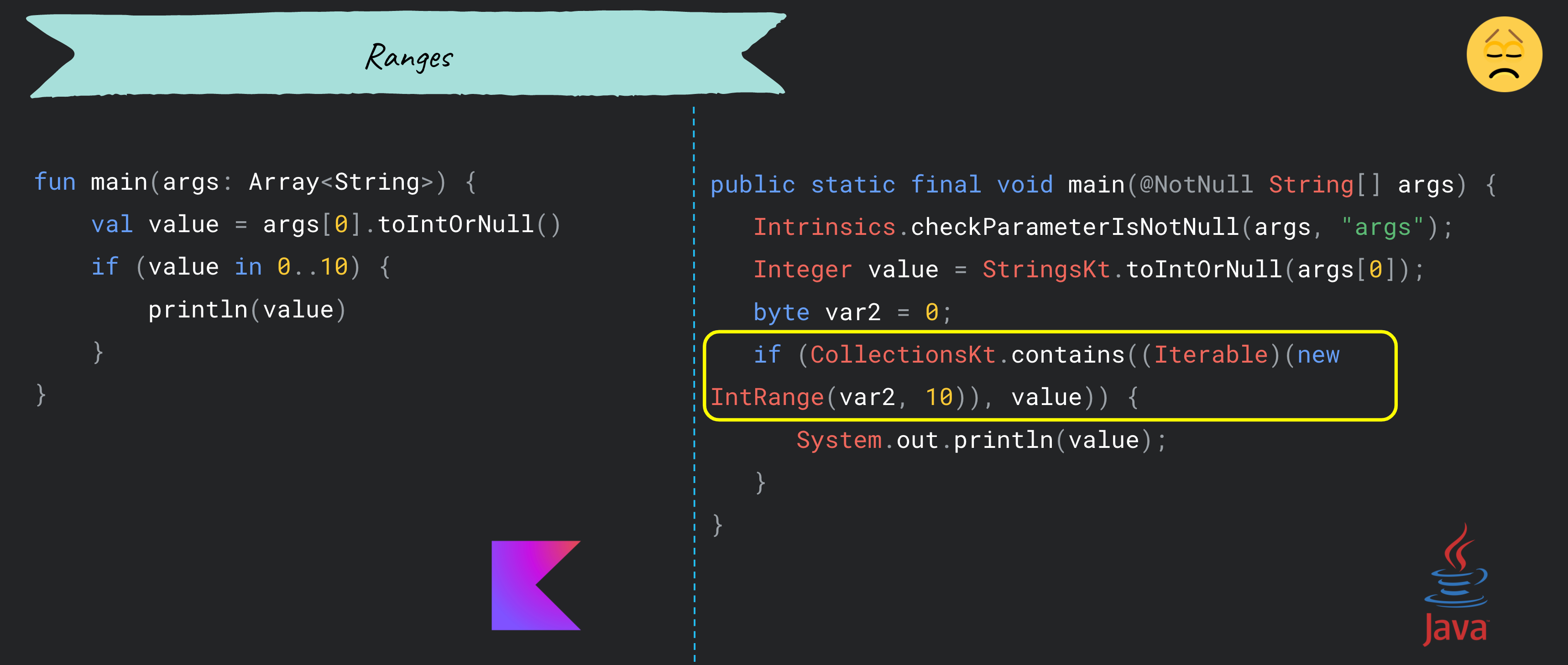
- 범위 값을 변수에 할당하면 객체가 생성됨으로 사용하지 않는 것이 좋다.
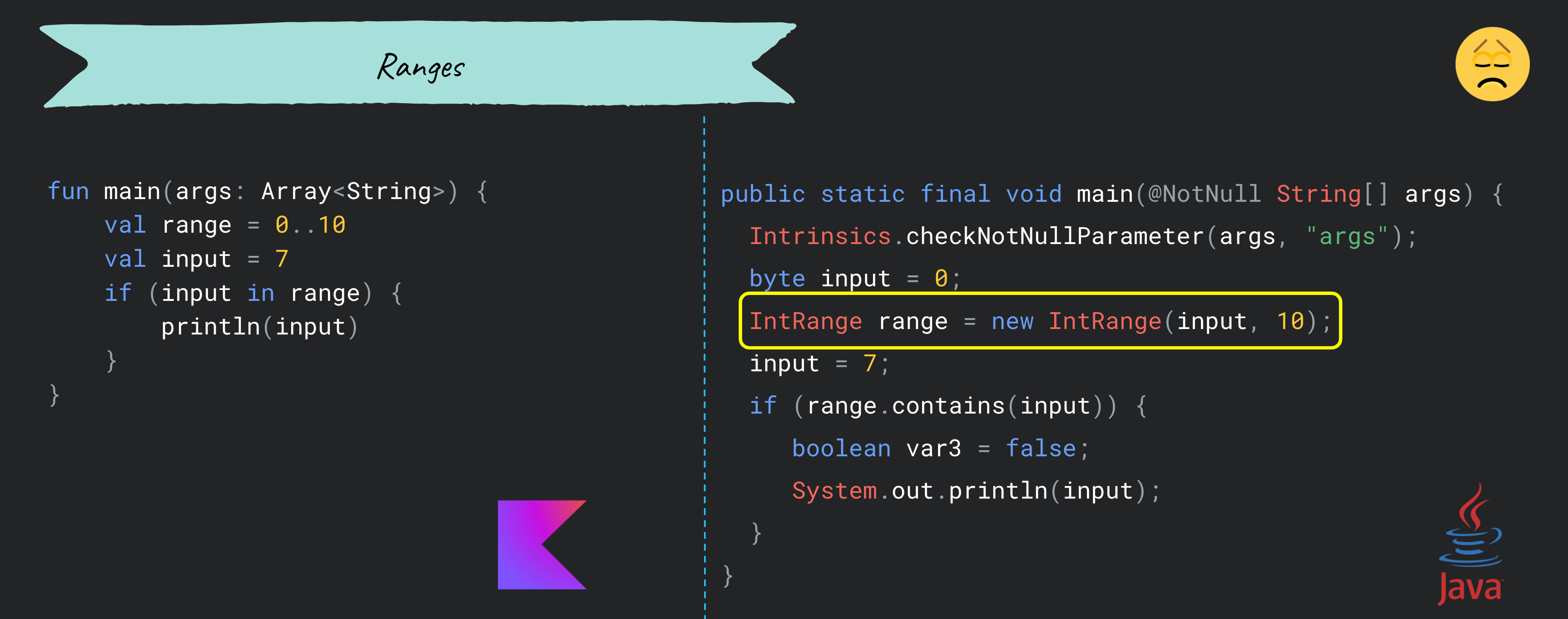
- 옳은 방법은 아래와 같이 가장 기본적으로 사용하는 방식이다.

'Kotlin' 카테고리의 다른 글
| [TIL] Effective Kotlin을 읽어보자 - 책 소개편 (0) | 2022.03.04 |
|---|---|
| [TIL] Exception handling in Kotlin Coroutines (0) | 2022.02.23 |
| [TIL] Kotlin Coroutine Cancellation (0) | 2022.02.15 |
| [TIL] 코틀린 코루틴에서 어떻게 지연 - 재개가 이루어지는가? (0) | 2022.02.12 |
| [TIL] Inline functions (0) | 2022.02.10 |
